Free starter
Free
For proving MemQ on one AI workflow before adding billing or a team.
$0.00/moNo Stripe checkout
100 memory segments
25 writes / 150 reads per month
5 AI calls / 2,500 AI tokens per month
_commons plus one private namespace
Governed memory for AI work that needs continuity.
MemQ captures decisions, preferences, run history, and team knowledge so every approved AI tool can start with the context that already exists.
Works with the AI tools people already use
Keep preferences, fixes, and project facts alive across the AI tools you already use.
Turn handoffs, runbooks, and decisions into reusable intelligence for the whole workflow.
Use namespaces, audit records, and rollout controls when AI context becomes business-critical.
Start free: connect one tool, save one decision, restart, and verify recall. Upgrade when MemQ becomes the operating context for real projects, client work, or team handoff.
# Codex plugin + skill codex plugin marketplace add https://github.com/multinex-ai/memq.git codex plugin install memq-brain@multinex-memq-codex # Or use the standalone skill bundle open /downloads/memq/skills/codex/memq-operations/SKILL.md
Your agent auto-discovers 35 hosted MCP tools on connect.
Get API keyMemQ in plain English
MemQ makes your AI remember the work you already paid it to understand: the decision, the preference, the fix, and the next handoff.
Recall
Useful context
Approved decisions and notes can return when the next AI run starts.
Runbooks
Reusable steps
Preferences, fixes, and team patterns can become repeatable context.
Namespaced
Separated memory
Namespace checks keep private work and team memory separated.
Any agent
Governed memory
One approved memory path works across your AI tools and MCP agents.
Without memory
Every new chat starts from zero.
With MemQ
The next AI run starts with the decisions you already approved.
Without memory
You hunt through old threads to find the fix.
With MemQ
MemQ recalls the right note first, then shows where it came from.
Without memory
Team handoff means pasted summaries and missing context.
With MemQ
Save the handoff once and approve it into shared memory.
Without memory
Each agent keeps its own context silo.
With MemQ
MemQ carries approved context across any connected agent.
Built for everyone using AI
MemQ makes AI remember useful work, transfer context between agents, and compound team knowledge without forcing every memory into the same shared bucket.

MemQ keeps preferences, project facts, decisions, prompts that worked, and what to avoid next time.
Private memory first
Codex, Gemini-style clients, Claude, Cursor, and VS Code can recall repo rules, decisions, migrations, and review lessons without rereading everything.
Agent memory in your tools
Save the decision once, approve it into team memory, then let another teammate or agent resume with the same context.
Shared namespace continuity
Namespace isolation, audit-friendly journal records, and team-level memory policies turn AI memory into infrastructure instead of unmanaged chat history.
Procurement-ready posture
Start personal. Promote only the context the team should share.
For individual AI users
Your daily AI usage gets durable recall without forcing team sharing.
For shared work
Approved decisions, runbooks, and handoffs become reusable across people and agents.
For autonomous workflows
Background agents, OpenClaw operators, and CI workflows can save and recall state through the same MCP contract.
Capacity scales with usage, not with confusing setup paths.
Free
25 writes / 150 reads
100 memory segments
Contributor
250 writes / 1,500 reads
1,000 memory segments
Pro
1,500 writes / 7,500 reads
3,000 memory segments
Team
7,500 writes / 15,000 reads
11,250 memory segments
Before MemQ vs after MemQ
Memory should feel like continuity, not another database project. MemQ helps your next AI session remember the decisions, handoffs, and preferences that already matter to you.

MemQ helps important context stay usable across sessions, tools, and approved team handoffs.
The re-explain tax
Cold starts turn good AI into repeated setup: explain the project again, paste the old thread again, rebuild the handoff again, and hope the next run catches up.
MemQ difference
Save personal preferences and project facts first. When a decision needs handoff, approve it into team memory so the next teammate or agent can continue from the same place.
Personal continuity
Keep preferences, decisions, and project facts available when the next AI session starts.
Team handoff
Move approved context into shared memory so another teammate or agent can continue the work.
Governed growth
Start small, then add namespaces, usage visibility, and team controls when the workflow is ready.
MemQ uses semantic recall where it helps, but wraps it in HOT recent state, durable journal evidence, graph-aware relationships, and reflection.
The product surface is MCP-first: tools can save context, retrieve it, checkpoint it, and hand it from one assistant to another.
Private work can stay private while approved decisions move into team memory for developers, operators, and enterprise rollouts.
MemQ ships operating guidance for Codex, Claude Code, OpenClaw, Legion, and generic MCP agents instead of leaving users with raw API docs.
MemQ plugins and skills
MemQ ships ready paths for Codex, Hermes, OpenClaw, Claude Code, Gemini-style clients, and standard MCP agents. Connect once, save the decision, and let the next tool resume with context.
Endpoint
https://mcp.multinex.ai/mcp/v1Connect to the hosted MCP endpoint.
Auto-discover 35 memory, journal, brain, and system tools.
Use the bundled skill to recall before planning.
Save a checkpoint or handoff without leaking secrets.
Team Handoff live preview
MemQ turns a saved decision into working context for another model, agent, teammate, or governed enterprise namespace.

Source
Backend agent
Target
Frontend agent
add_memory
Checkout payload now includes billingInterval and productSlug. Approved handoff: preserve the query params in every CTA.
hybrid_retrieve
Resume the checkout CTA work from the approved team handoff.
Save decision
The first agent writes the reusable decision, not the whole transcript.
Approve namespace
Private work stays private until the useful handoff moves into team memory.
Recall instantly
The next agent retrieves the exact context needed to continue.
Resume work
The user sees continuity instead of another cold-start prompt.
Namespace boundary: team:checkout
Context handoff can stay private, move to a team, or be constrained to an org namespace as the workflow matures.
Dreamer Daemon
The Dreamer Daemon is the autonomous memory lifecycle behind MemQ. It wakes after meaningful MCP activity or on a schedule, compresses the useful signal, reflects on what changed, reinforces lessons, and leaves the next agent with context it can actually use.
MCP tools write memories, journal records, handoffs, and checkpoints.
Session-end or scheduled Dreamer wakes the consolidation cycle.
Reflection produces validated learning, not loose model chatter.
MemQ writes the result back into recall, replay, and resume surfaces.
Dreamer uses the authenticated MemQ contract, so reflection and resume behavior stay inside the same subscription, namespace, and metering boundary as the hosted MCP.

35 tools feed memories, journals, plans, and handoffs into the lifecycle.
Session end and scheduled cycles wake Dreamer without requiring a user to babysit recall.
Dreamer
Daemon
HOT
runtime state
WARM
vector recall
COLD
journal evidence
ENGINE
plan resume
Recent memories and journal records are compressed into patterns instead of forcing every agent to reread raw session history.
A routed model lane turns outcomes, failures, and contradictions into schema-valid learning checkpoints.
High-signal lessons become future planning priors, so the next agent starts closer to the right decision.
Reusable findings can be proposed for review without publishing private memory directly into shared commons.
System Architecture
MemQ is not a loose vector database behind a chatbot. It is an authenticated runtime where billing, gateway policy, MCP tools, memory tiers, reflection, and governed commons all have a defined role.
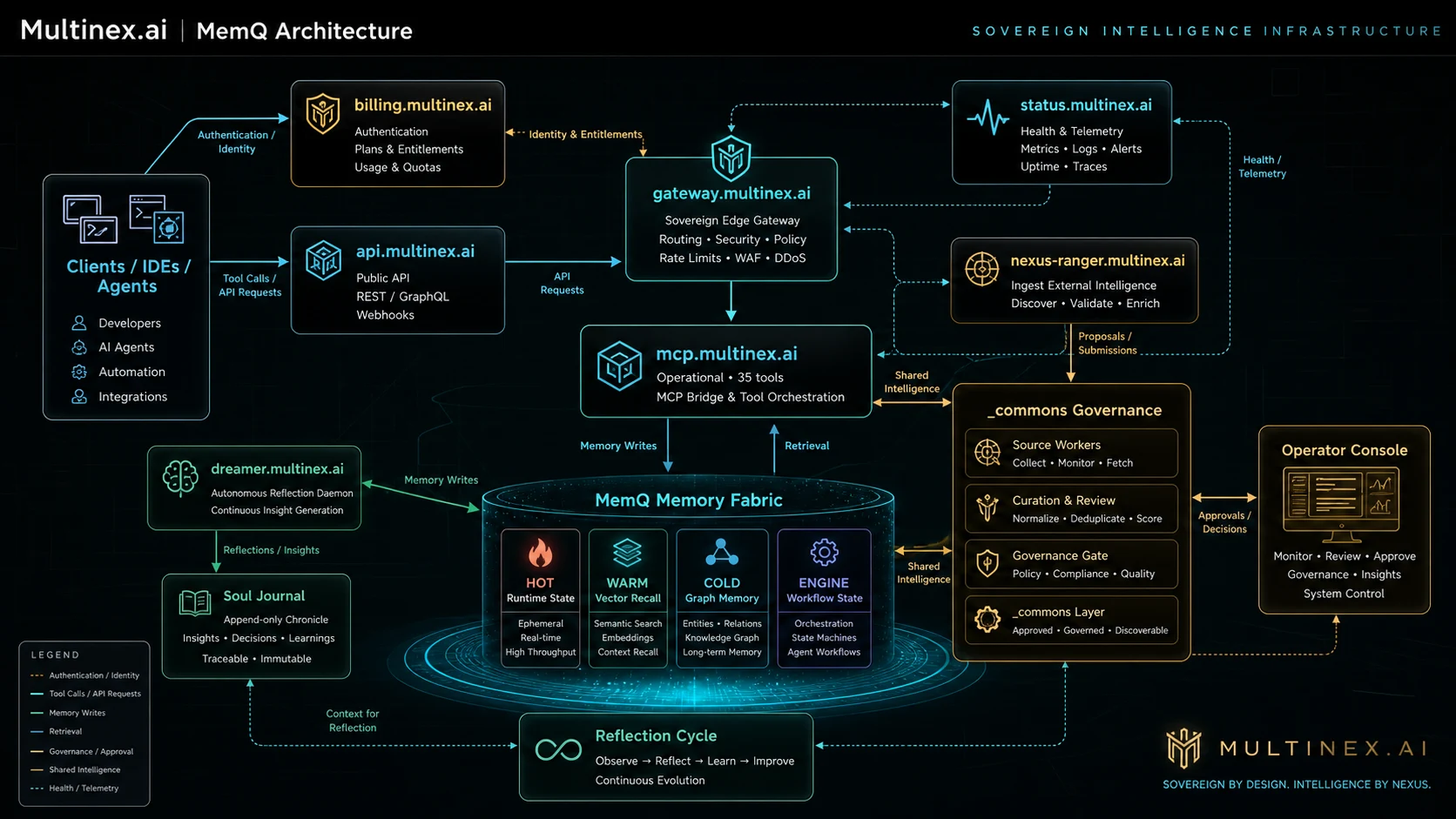
Private, team, and governed commons memory route through one gateway.
Billing, namespace, policy, and entitlement checks happen before durable writes.
Dreamer, Soul Journal, and reflection turn finished work into reusable context.
HOT, WARM, COLD, and ENGINE tiers keep recall useful across sessions.
Drop in our MCP snippets and pre-built templates to get started in minutes. Turn stateless scripts into learning systems instantly.
# 1. Save one real decision add_memory "This repo requires Zod at IO boundaries." # 2. Restart the agent session # 3. Recall it without re-prompting search_memory "Zod IO boundary rule"
A breakthrough in model interoperability. MemQ translates embedding dimensions on demand through a lossless passthrough fabric, making your architecture completely AI vendor agnostic.
Plans & pricing
MemQ Free activates through Billing Manager without a Stripe checkout and gives one builder enough room to try recall. Pro gives heavier workflows more room. Team adds shared memory when approved decisions need to move between people and agents.
Activation path
For proving MemQ on one AI workflow before adding billing or a team.
$0.00/moNo Stripe checkout
For solo builders and operators who want their AI tools to remember real project work, client context, and decisions.
$20.00/moBilled monthly
For heavier AI workflows that need more recall volume, stronger validation, and priority capacity.
$50.00/moBilled monthly
For shared team memory, handoffs, activity history, and approved context across multiple users.
$99.99/mo orgBilled monthly
Enterprise rollout
Use the demo path when rollout needs shared namespaces, admin controls, customer data handling, or agent workflow workflow planning before checkout.
Trial availability, renewal timing, and billing method requirements are confirmed in Billing Manager before activation.
Make the next run remember
Connect one AI tool, save one useful decision, switch sessions or agents, and verify recall before you move team work into MemQ.